자바를 공부해보았다면 익히 들었을 JVM, Java Virtual Machine 에 대해서 이야기해보려 한다.
막연하게 JVM 이 동작하고 JVM이 있기 때문에 플랫폼에 독립적이며 Garbage Collection 으로 장점을 얻을 수 있다고 생각하는 사람들이 많을 것이다.
오늘은 JRE의 구성요소인 JVM이 어떻게 구성되고 Garbage Collection 이 어떤 방식으로 동작하는지 알아볼 것이다.
JVM 이란?
지난 2번의 시간에 거쳐 우리는 Java Bytecode와 Java ClassLoader 에 대해서 알아보았다.
지난 시간에는 어떻게 자바 파일이 컴파일되어 클래스 파일로 변환이 되고, 어떻게 클래스로더에 의해서 동적 적재되며 verification 을 수행하는지 알아보았다.
오늘은 그 이후에 일어날 클래스로더에 의해서 로드된 바이트코드가 Runtime Data Areas 에 로드되고 Execution Engine 이 로드된 바이트코드를 실행하는 부분에 대해서 알아보려 하고 이것이 바로 JVM이 하는 일이다.
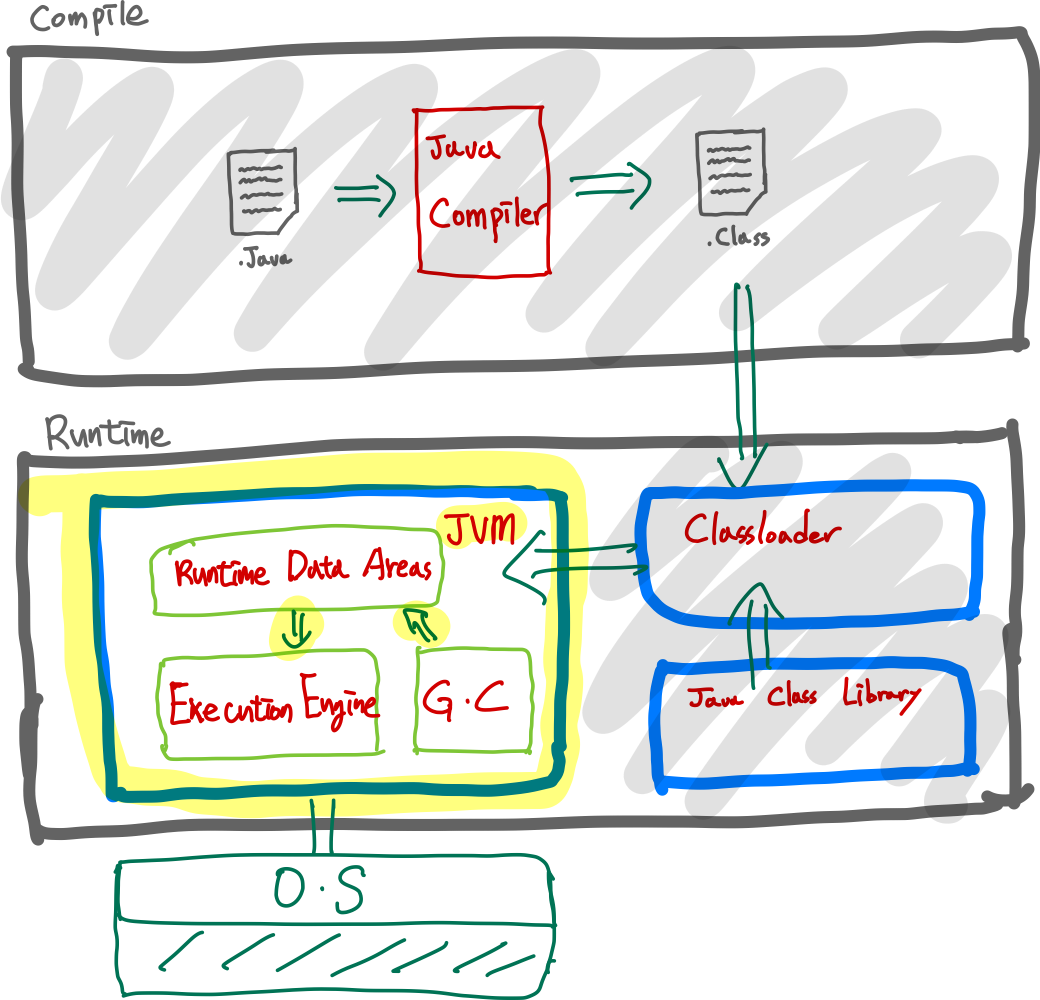
JVM은 Java Virtual Machine 으로 Host Machine 내에서 독립적으로 돌아가는 Machine 이기 때문에 익히 들었을 자바의 이식성이라는 특징이 나오게 된다.
JVM은 크게 2가지 종류가 있다.
- Stack Based Machine
- Register Based Machine
1. Stack Based Machine
우리가 일반적으로 사용하는 JVM이 모두 스택 기반 머신이다.
스택 기반 머신은 target hardware 에 대한 종속이 적기 때문에 이식성이 뛰어나야하는 VM에서 자주 사용된다.
하지만 Stack 의 특성을 따라야 하기 때문에 단순 덧셈의 연산에도 4단계 명령이 필요한 경우가 있다.
POP 10
POP 20
ADD 10, 20 RESULT
PUSH RESULT우리가 일반적으로 사용하는 Stack Based JVM에서는 Oracle의 Hotspot JVM과 Eclipse의 OpenJ9 가 존재한다.
Oracle의 Hotspot JDK 는 CPU 효율이 좋다는 특성이 있고 OpenJDK의 OpenJ9 은 메모리 효율이 좋다는 특성이 있는데, 이 두 JDK의 비교는 아래에서 참고할 수 있다.
2. Register Based Machine
특수한 경우와 목적에만 사용되는 JVM 인데, 안드로이드의 Dalvik JVM이 그렇다고 한다.
Dalvik JVM은 일반 JVM의 명세를 따르지 않는 대신 효율과 성능이 우수하다.
- 30% fewer instruction
- 35% fewer code units
- 35% more bytes in instruction stream
이라는 장점과 특징이 존재하지만 하드웨어 (안드로이드)에 종속적이라는 특성으로 인해서 이식성이 뛰어남을 포기한 case 라고 할 수 있다.
JVM 의 구성요소
JVM 에서는 크게 3가지의 구성 요소가 존재한다.
- Runtime Data Areas
- Execution Engine
- Garbage Collection
하나 하나 각각 알아보자
1. Runtime Data Areas
자바의 메모리 구조로 불리기도 하는 Runtime Area 는 클래스로더가 Bytecode 를 로드하는 대상 메모리 영역이다.
이는 OS로부터 할당받는 실제적 메모리 공간으로 우리가 구성한 모든 코드의 동작은 이 메모리 위에서 동작하게 되는 것이다.

Runtime Data Area 는 Thread로 구분할 수 있는데, Thread가 다른 Thread 와 공유하는 여부와 공유하지 못하는 여부에 따라서 나뉠 수 있다.
Thread 별로 생성되는 영역 : PC Register, JVM Stack, Native Method Stack
- PC Register
- Program Count Register 는 현재 수행 중인 JVM Instruction 주소를 갖는다.
- Register Based 인 CPU 내의 PC와는 다르게 Stack-Based 로 동작한다.
- JVM Stack
- Thread 의 Method 가 호출될 때의 수행 정보와 같은 StackFrame 의 정보, 메서드 호출 주소, 매개변수, 지역변수와 같은 수행 정보를 나타낸다.
Exception.printStackTrace()에 나오는 정보가 바로 JVM 스택의 정보이다.
- Native Method Stack
- Java 외의 언어로 작성된 Native Code 를 위한 별도의 Stack이다.
- JNI 를 통해서 호출되는 C나 C++의 코드에 맞게 스택이 생성된다.
모든 Thread 가 공유하는 영역 : Heap, Method Area, Runtime Constant Pool
- Heap
- 일반적인 Heap Memory 라고 생각하면 된다.
- 인스턴스나 객체, 배열 등을 동적으로 저장하는 공간으로 이곳이 바로 Garbage Collection의 대상이 되는 공간이다.
- JVM 성능 이슈에서 가장 많이 언급되는 공간이기도 하다.
- Method Area
- ClassLoader 가 적재한 클래스에 대한 메타데이터 정보가 저장되는 공간이다.
- 논리적으로 Heap 에 포함되는데 PermGen 이라는 영역이다
- Java 8 이후부터 Metaspace OS가 관리하는 공간으로 옮겨지게 된다.
- 이는 추후에 기회가 된다면 따로 포스팅을 하도록 하겠다.
- Runtime Constant Pool
- Method Area 내부에 속한 영역으로 모든 Constant 레퍼런스를 저장한다.
- 이외에도 Class Variable, Field Information, Type Information 등이 Method Area 에 포함되어 있다.
2. Execution Engine
실행 엔진, Execution Engine 은 Runtime Data Area 에 잘 할당된 Bytecode 를 실행시키는 일을 수행한다.
CPU는 Java Bytecode 를 바로 실행시킬 수 없다.

그래서 Bytecode를 기계어로 변환하는 과정이 꼭 필요한데, 이 과정으로 인해서 Java가 C나 C++에 비해 느리다고 한다.
Bytecode를 명령어 단위로 읽고 번역하는 방식은 크게 2가지로 나뉘게 된다.
- Interpreter 방식
- JIT(Just In Time) 컴파일 혹은 동적 번역 방식
Interpreter 방식은 각 OS 플랫폼에 맞는 인터프리터가 바이트 코드를 실행(번역)하는데, 바이트 코드를 한 라인씩 읽고 실행(번역)을 하게 된다.
하지만 한 라인씩 읽는 Interpreting 방식에 속도 issue 가 동반된다.
이 때 자주 실행되는 바이트 코드 영역을 기계어로 통으로 컴파일하는 것이 바로 JIT 컴파일러이다.
JIT 컴파일러를 사용한다면 자주 사용되는 바이트 코드영역을 기억했다 한 번에 컴파일하기 때문에 속도가 조금 빨라지게 되는 것이다.
아래의 코드는 Junhyunny 님의 블로그 에서 JIT를 테스트하는 코드를 가져온 것이다.
public class JitCompilerTest {
public static void main(String[] args) {
int a = 0;
for (int index = 0; index < 500; index++) {
long startTime = System.nanoTime();
for (int subIndex = 0; subIndex < 1000; subIndex++) {
a++;
}
System.out.println("loop count: " + index + ", execution time: " + (System.nanoTime() - startTime));
}
}
}
이 결과는 시간이 지날수록 실행되는 속도가 빨라지는데, 이는 JIT 컴파일러가 동작하기 때문이다.
loop count: 0, execution time: 8300
loop count: 1, execution time: 9000
loop count: 2, execution time: 8300
...
loop count: 51, execution time: 8100
loop count: 52, execution time: 890200
loop count: 53, execution time: 8500
...
loop count: 109, execution time: 231500
loop count: 110, execution time: 7700
loop count: 112, execution time: 1600
...
loop count: 335, execution time: 36000
loop count: 336, execution time: 3000
loop count: 337, execution time: 0
...
JIT 컴파일러는 위의 내용으로 알 수 있지만 같은 코드를 매번 해석하지 않고 캐싱을 하여 재호출이 일어나면 캐싱된 코드를 사용한다.
3. Garbage Collector
Garbage Collector은 JVM의 성능과 가장 연관이 있는 Runtime Data Areas 의 Heap 영역의 동적 할당 데이터들을 관리하는 역할을 한다.
관리라면 당연히 사용되지 않는 메모리를 지속적으로 관찰하고 찾아서 제거라는 의미가 포함되어 있다.
Java 에서는 c나 c++과 다르게 malloc 과 free 와 같이 개발자가 프로그램의 코드로 메모리를 해제하는 과정이 없는 이유도 잘 알다싶이 바로 GC가 있기 때문이다.
GC는 Weak Generational Hypothesis 라는 약한 세대 가설에 기반한다고 한다.
약한 세대 가설에서는 2가지 Generation이 존재한다.
- Young Generation
- 객체가 생성되는 순간 이곳으로 이동한다.
- 만약 Young Generation 이 가득 차면 Minor Collection 이 발생한다
- Minor GC가 발생하면 살하있는 객체들만 확인하고 나머지를 버린다.
- 살아남은 객체중 더 오래 쓸 것 같은 객체를 Tenured Generation 으로 이동시킨다.
- Tenured Generation
- Young Generation 에서 오래 살아남은 객체가 위치하게 된다.
- 역시 Tenured Generation 가 가득차면 Major Collection이 발생한다.
위의 두 영역에 대해서 Minor GC와 Major GC가 동작할 때 다음의 2가지 공통적 단계를 따르게 된다.
- Stop The World
- Mark And Sweep
1. Stop The World
Stop The World 는 GC를 실행하기 위해서 아주 잠깐 JVM이 Application 의 실행을 멈춘다.
이 때 GC가 동작하는 Thread 를 제외한 나머지 Thread 의 작업이 중단되고 Collecting 과정을 거친 후에 다시 Thread 가 실행이 된다.
GC가 멈추면 자연스럽게 우리의 눈에는 Latency 가 발생하게 되고 GC 성능 개선이라고 하면 Stop-The-World 시간을 줄이는 것이라고 한다.
2. Mark And Sweep
Stop The World 를 통해서 모든 스레드의 작업을 중단시키면, GC는 동적 객체에 대한 탐색을 수행한다.
객체가 점유하는 메모리를 식별하는 과정을 Mark 과정이라고 하는데, Mark 과정이 되지 않았다는 소리는 객체가 점유하고 있는 메모리가 존재하지 않는다는 이야기이므로 해당 메모리를 제거한다.
메모리를 제거하는 과정이 바로 Sweep 이라고 한다.
- Garbage Collector
- JVM이 동적으로 사용되지 않는 메모리를 지속적으로 찾아서 제거하는 역할
- 실행 순서
- 참조되지 않은 객체들을 탐색 후 삭제 -> 삭제된 객체의 메모리 반환 -> 힙 메모리 재사용
'💊 Java & Kotlin & Spring > - Java & kotlin' 카테고리의 다른 글
| 다형성을 위한 instanceof 를 Generic 으로 제거하는 방법 (0) | 2022.04.03 |
|---|---|
| [조금 더 깊은 Java] JRE의 Classloader 에 대해 알아보자 (0) | 2021.12.02 |
| [조금 더 깊은 Java] Java Bytecode 를 알아보자 (자바를 컴파일하면 어떤 일이 일어날까?) (2) | 2021.11.25 |
| [조금 더 깊은 Java] String 과 String Constant Pool (1) | 2021.11.23 |
| [Java] Arrays.copyOfRange 로 범위 만큼 배열 복사하기 (0) | 2021.07.05 |




댓글